Softwaremodernisierung mit GenAI – The Good, the Bad, the Unexpected
Mein erster Vortrag über die Softwaremodernisierung mit KI
Abstract
Neuen Code mit Large Language Models zu erzeugen, ist für uns längst keine Neuheit mehr. Doch der Traum, alte Softwaresysteme per Knopfdruck mithilfe künstlicher Intelligenz zu modernisieren, ist noch weit entfernt. Alte Softwaresysteme sind – sagen wir – doch etwas spezieller. In diesem Vortrag zeige ich, wie generative KI (GenAI) in diesem Bereich dennoch schon heute sinnvoll eingesetzt werden kann, wo wir (noch) an Grenzen stoßen und wo bei der Zusammenarbeit mit unseren modernen KI-Kollegen ganz andere, unerwartete Effekte auftreten.
Einleitung

Bevor es losgeht: Dieser Vortrag gliedert sich in drei Teile: The Good, The Bad und The Unexpected.
Und: Der Fokus liegt nicht darauf, wie man GenAI in Software einbaut – dafür gab es andere Beiträge auf der Veranstaltung. Es geht um das Warum und das Wie: Wie kann man mit GenAI Legacy-Systeme modernisieren? Was funktioniert gut, wo muss man aufpassen, und welche unerwarteten Nebeneffekte entstehen, wenn man mit generativer KI in Legacy-Code herumwühlt?
Hintergrund: Von der Analyse zur Modernisierung

Ich beschäftige mich schon länger mit dem Thema Legacy-Modernisierung. Wenn man einmal ein System erfolgreich nach vorne gebracht hat, bleibt man dabei. Und es gibt gute Tools, um großflächig Legacy-Systeme zu analysieren – statische und dynamische Analyse, Bottlenecks zur Datenbank finden und so weiter. Das habe ich lange für Architekturreviews gemacht.
Irgendwann wurde das aber mühselig. Etwa 2014 kam für mich dann das Thema Data Science ins Spiel. Data Science passt gut zu Analyseaufgaben in der Softwaremodernisierung: Man muss sauber Analysen durchführen, fast schon wissenschaftlich. Schritt für Schritt vorgehen und zeigen, was man mit den Daten macht. Aber vor allem wichtig: Reproduzierbarkeit! Nicht einmal irgendwie eine Analyse zusammenschustern, sondern es muss immer wieder funktionieren und wiederholbar sein. Für die gleichen Daten soll das gleiche Ergebnis rauskommen – und das funktioniert nur durch einen hohen Grad an Automatisierung.

Das hat für mich wunderbar bei Legacy-Modernisierungen und Code-Analysen gepasst. Einerseits strukturierter vorgehen, andererseits automatisierte Analysen. Also großflächig Code analysieren, ohne manuell Dashboards zu bedienen. Und: Direkt dann auch im Code zeigen, was los ist.
Das klappte sogar so gut, dass ich teils sogar Verbote bekommen habe zu analysieren, weil ich so viele Probleme gefunden habe, welche nicht von der Hand gewiesen werden konnten. Aber es gab auch ein grundlegendes Problem: „Vom Wiegen wird die Sau nicht fett”, wie man sagt. Oder anders ausgedrückt: Man kann noch so viel analysieren und Probleme aufzeigen, aber ohne Arbeit zu deren Lösung ändert sich hier leider gar nichts.
“Computer, fix mein Code” – Eine neue Hoffnung

Ein paar Jahre später, im Februar 2020, blickte ich noch einmal auf die zwischenzeitlichen Veränderungen im Bereich „Code als Daten”. Ich habe dort den Vortrag namens „Computer, fix mein Code” gehalten – über Machine Learning on Code in der Praxis. Damals gab es schon erste Ansätze, Code zu fixen und auch neu zu generieren. Die Technik lief damals aber noch nicht so richtig gut.
Aber es waren bereits die ersten Schritte und die Hoffnung auf eine bessere Zukunft zu sehen.
Heute sind wir bei GenAI angelangt – oder genauer gesagt: Large Language Models und GPTs. Die Hoffnung ist nun Realität geworden: Diese Techniken nutzen wir heute, um Code zu schreiben und auch – im besten Falle – um Legacy-Systeme strukturiert zu modernisieren; und das großflächig und hochautomatisiert.
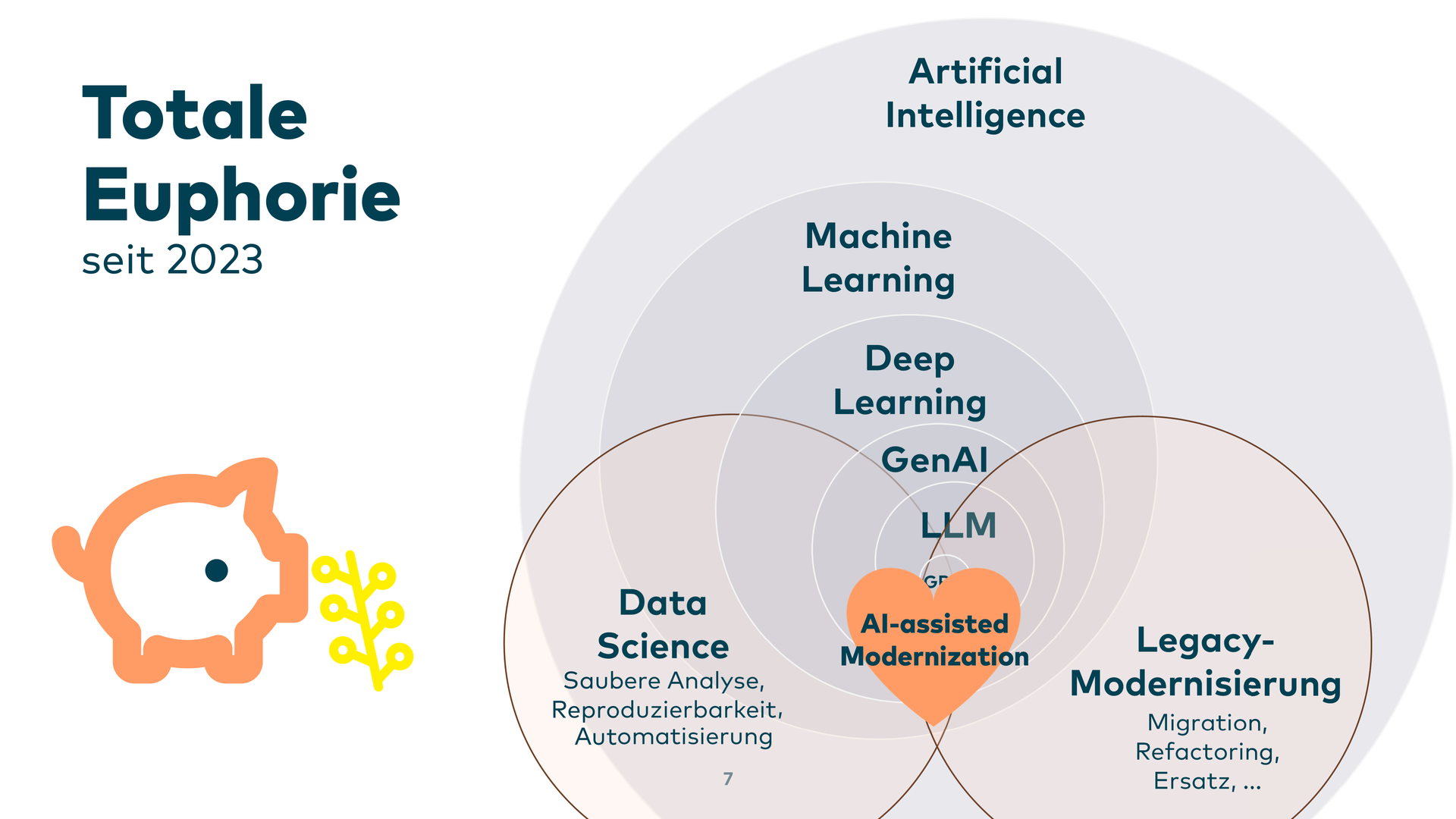
Ich bin auch voller neuer Hoffnung hier mit dabei. Ich habe noch nicht fundamental harte Grenzen gesehen, woran diese neue Art Code zu erzeugen scheitern könnte. Man muss sich aber bewusst sein: alles ist noch ein zartes Pflänzchen. Aber: Es ist nicht mehr so, dass man nur das Schwein wiegt. Nein, jetzt bekommt das Schwein endlich auch Futter - oder anders gesagt: nun können wir gefundene Probleme durch LLMs auch endlich automatisiert beheben lassen.
GenAI in Allgemeinen hat das Porzenial, uns im Umgang mit Legacy-Systemen extrem weiterzuelfen. Zwar nicht auf Knopfdruck, also als Zauberer, der kommt und ein super gutes System hinterlässt. nein, das ist eine Illusion. Aber es gibt zumidnest Ansätze, wo uns GenAI und Large Languasge models sehr gut auch im LEgacy umfeld weiterhelfen .
The Good: Was schon geht
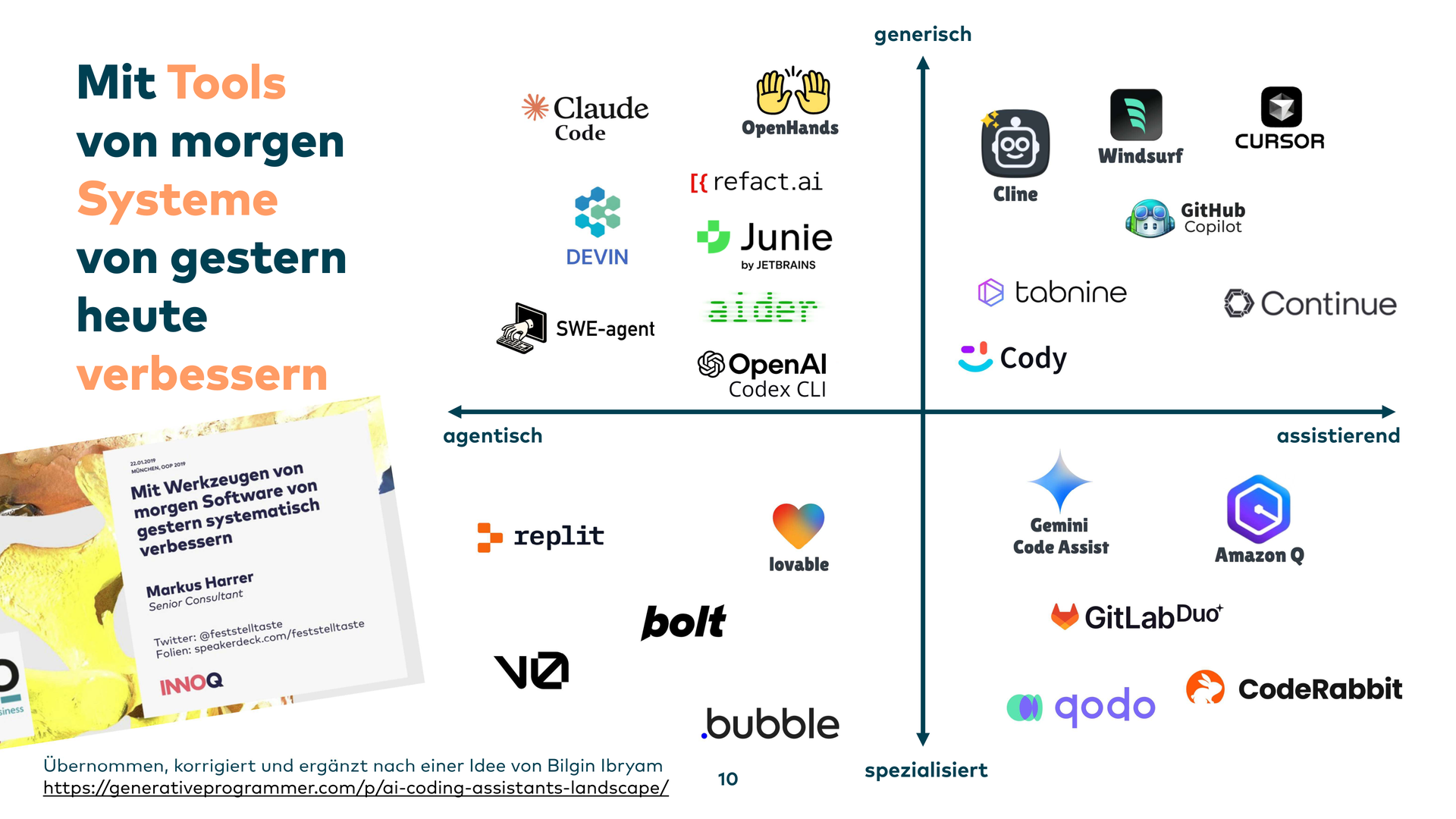
Was sind diese guten Seiten im Legacy-Umfeld? Einer der Hauptpunkte für mich: Man kann nun Legacy-Systeme von gestern mit Tools von morgen heute verbessern. Das ist eine unglaublich gute Motivation für Leute, die im Legacy-Umfeld unterwegs sind – man wird nicht aufs Abstellgleis gestellt, sondern darf endlich auch selbst wieder was Neues lernen.


Was sind die guten Seiten im Legacy-Umfeld? Einer der Hauptpunkte: Man kann Legacy-Systeme von gestern mit Tools von heute verbessern. Das ist eine unglaublich gute Motivation für Leute, die im Legacy-Umfeld unterwegs sind – man wird nicht aufs Abstellgleis gestellt, sondern kann wieder was Neues lernen.
Beispielsweise Tabnine. Da muss man auch rechtliche Dinge beachten: Woher kommt der generierte Code, wird da nur kopiert? Und man sollte sicherstellen, dass man im Stil des bestehenden Systems codiert – und nicht irgendetwas Komisches bekommt.

Was es auch gibt, sind integrierte Werkzeuge. Eines, das mir gefallen hat: Resolve-AI. Resolve-AI verschmilzt verschiedene Datenquellen miteinander und zieht daraus neue Erkenntnisse. Bei Incidents kann das Werkzeug direkt Handlungsanweisungen an Entwickler geben – auf Basis von Log-Dateien, Metriken und definierten Schwellenwerten, die nicht überschritten werden dürfen.
Das Werkzeug schaut dann auch in den Code auf GitHub: Wo genau ist das Problem aufgetreten, an welchem Einstiegspunkt in der Software? Dazu kommen Runbooks – typische Handlungsanweisungen für solche Situationen –, direkt ins Messaging-System eingebunden.
Das Ergebnis: Entwickler bekommen nicht mehr eine SMS mit „geht nicht”, sondern: „Hey, schau mal rein – in Databricks ist irgendwas kaputt, mach das.” Schnellere Reaktion auf Ausfälle in der Produktion. Das lässt sich auch im Legacy-System-Umfeld nutzen, um diese ständig ausfallenden Systeme ein bisschen besser unter Kontrolle zu bringen.
Ich habe ein Faible für Archäologie – ich wollte schon immer Dinosaurier ausgraben. Jetzt mache ich das im Code. Mit der Git-Historie kann man fragen: Was ist in dieser Komponente passiert, wie ist die entstanden? Large Language Models erstellen dann Zusammenfassungen, die sich aggregieren lassen – und so bekommt man ein Gefühl für die Geschichte, die Historie eines Software-Systems.
Zusammenfassungen der Historie sind eine der Paradebeispiele für Large Language Models. Das klappt fast schon erschreckend gut.
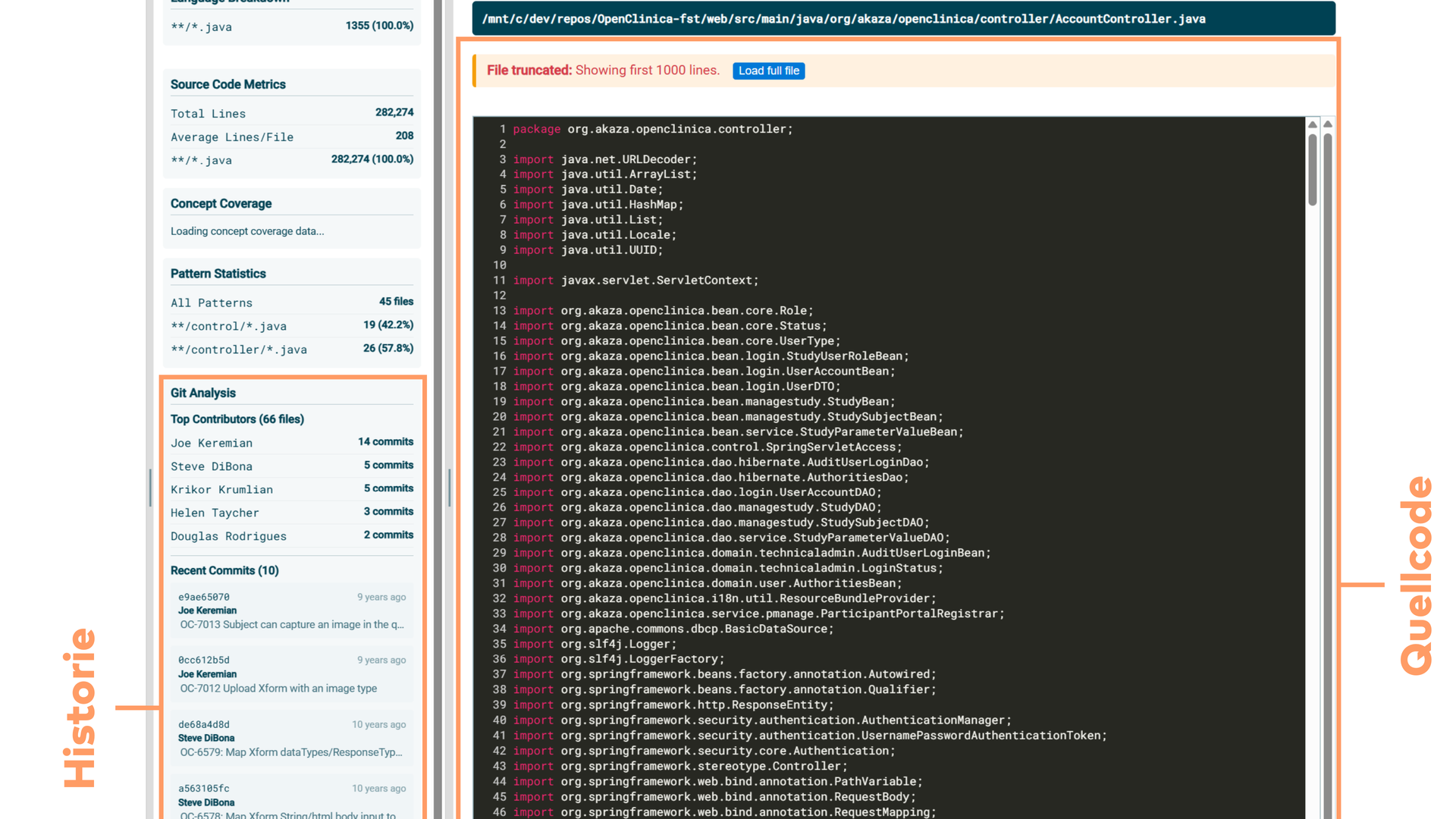
Code-Archäologie mit der Git-Historie


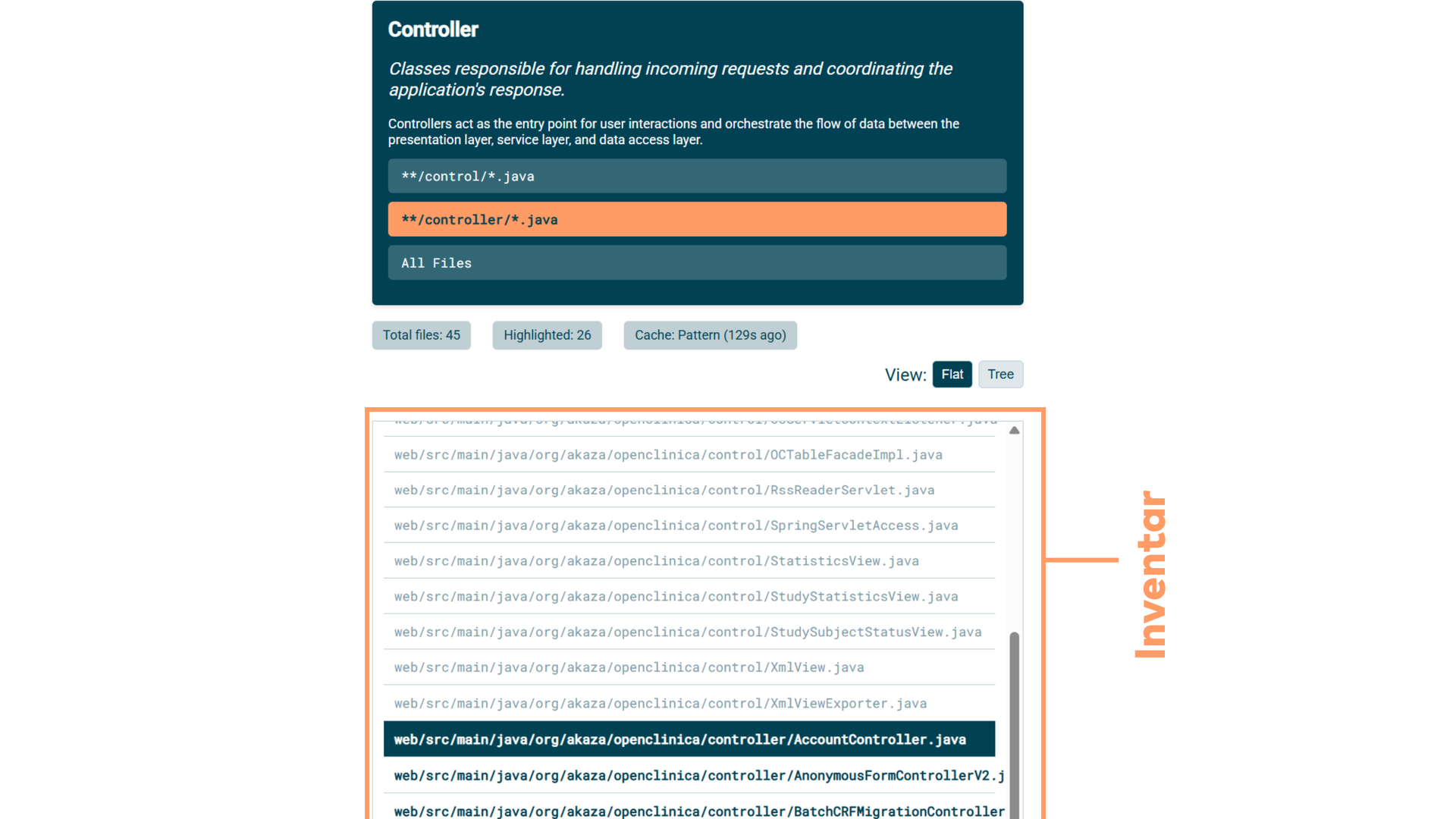
Und man kann sich Analyse-Tools auch sehr schnell selbst coden lassen – Vibe-Coding. Zum Beispiel, um bestimmte Strukturen wie Controller aus einer Code-Basis herauszufiltern, mit kurzer Beschreibung und Fundstellen.

Das Ergebnis: eine Art Code-Inventar. Welche Controller habe ich, wie viele? So bekommt man ein Gefühl dafür, was in der Code-Basis steckt. Und dann kann man noch prüfen, ob wirklich das drin ist, was draufsteht.
Das wurde mit Claude Code generiert, im InnoQ-Stil – und das Ergebnis war ordentlich. Es war auch keine große Sache.
Lokale Modelle
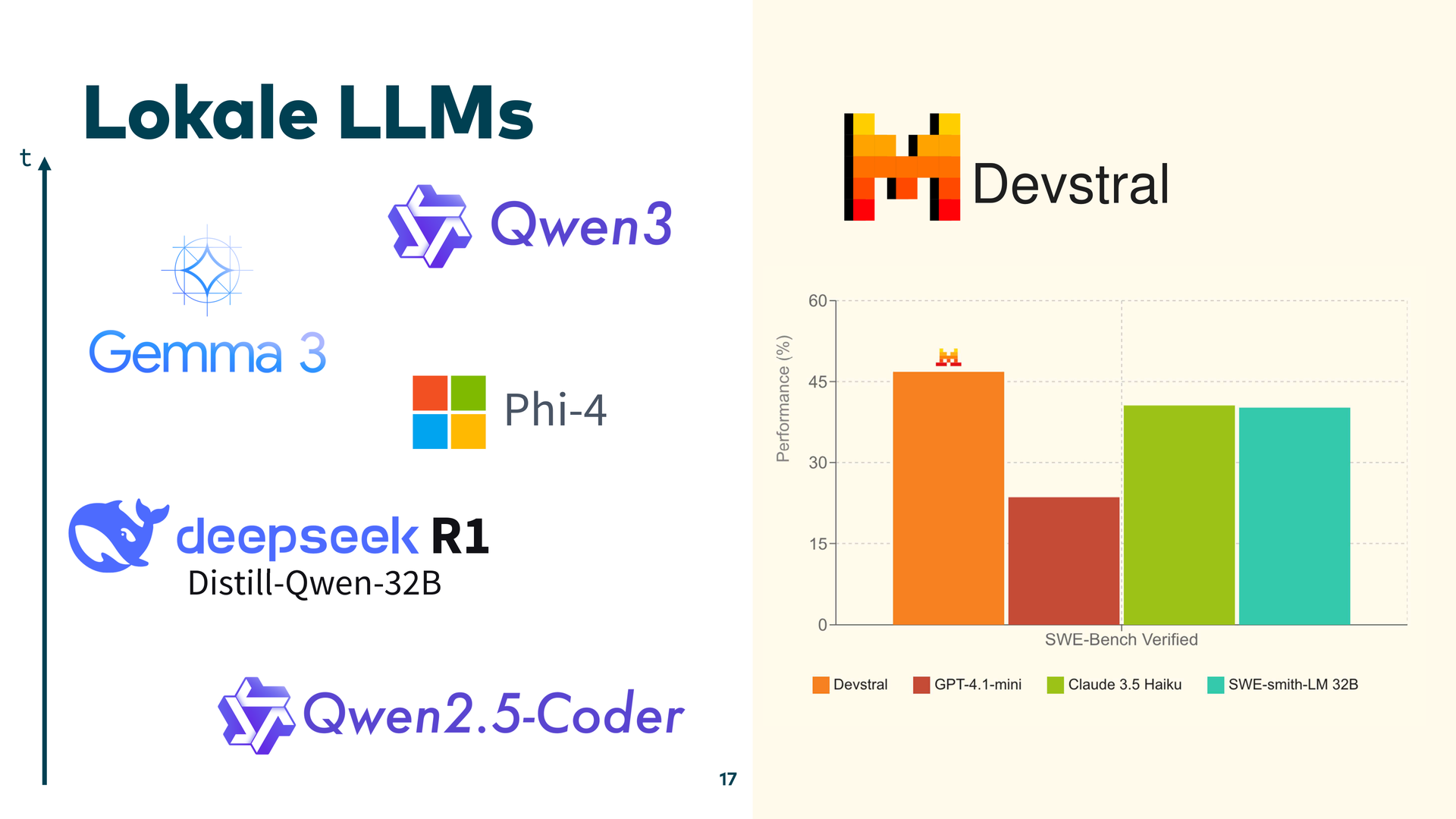
Ein weiteres Thema, das mich begeistert: Was man lokal, auf dem eigenen Rechner, machen kann. Kleine Modelle, die auf eine Grafikkarte passen – etwa Llama 3 oder das neue Devstral von Mistral. Die kann man auch dann nutzen, wenn man mit Kunden arbeitet oder wenn man Daten nicht nach außen geben darf.

Ob man sie für das komplette Umstrukturieren von Legacy-Code nutzen kann? Eher eingeschränkt. Aber: Die Leistungsfähigkeit der großen Modelle von vor einem Jahr haben die lokal laufenden Modelle mittlerweile in etwa erreicht.
Demo: Podcast aus Legacy-Code

Jetzt wird es ungewöhnlich. Ich wollte eine 8.000-Zeilen-Java-Klasse nicht durchlesen – also habe ich sie in NotebookLM geworfen, das daraus eine Podcast-Folge erstellen kann. . Das Ergebnis: Zwei KI-Hosts erklären den DataEntryServlet.java aus OpenClinica – auf Englisch, im Podcast-Format. „All right, everyone, get ready, because today we’re going deep, deep, deep into some Java code.” . Einfach mal zuhören, was da passiert im Code finde ich wesentlich angenehmer, als selbst Rätselratend alles selbst durchzugehen

Und warum nicht auch Video-Generierung? Vielleicht gibt es irgendwann ein TikTok-Video über den DataEntryServlet. Oder eine Komödie über das eigene Legacy-System, die Berührungsängste abbaut. Finde ich schön.
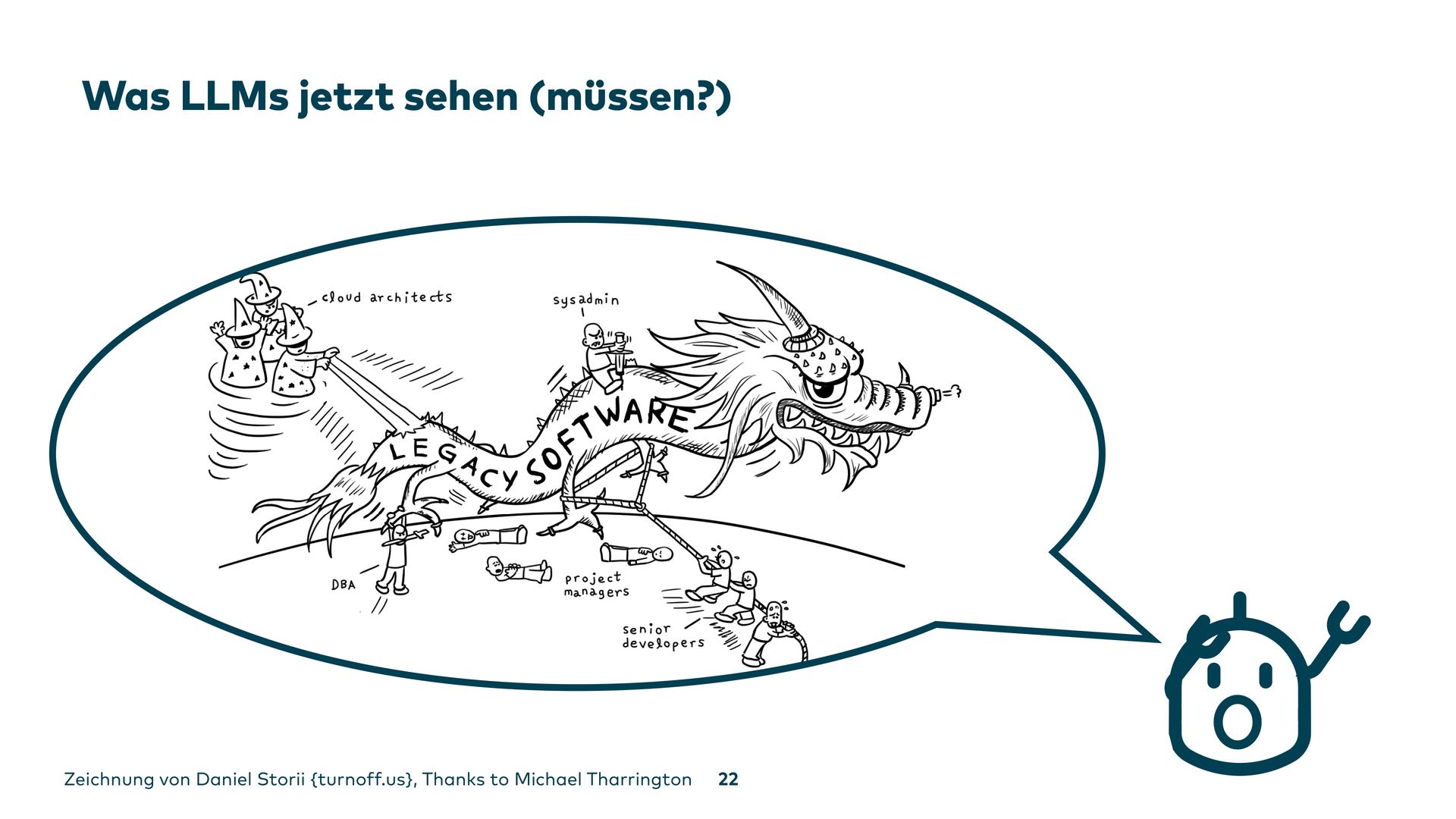
The Bad: Grenzen der Foundation Models im Legacy-Kontext
Jetzt zu den schlechten Seiten. Legacy-Systeme sind nicht die heile Welt. Man muss immer fragen: Was kann ich den Modellen abverlangen, was nicht?
Die Foundation Models – die großen Modelle von OpenAI oder Anthropic – wurden hauptsächlich an öffentlichen Projekten trainiert. Wer seinen Code öffentlich stellt, achtet schon darauf, dass er nicht zu peinlich ist. Es gibt viele Tutorials für die ersten Schritte in neuen Frameworks.
Das hilft auch beim Training der Modelle: So lässt sich Code in einem normalen Open-Source-Stil schreiben – auch im Legacy-Umfeld, so lange es nicht zu spezifisch wird. Aber wenn man das Modell auf das eigene System loslässt, sieht es anders aus. Ein LLM kann vielleicht gar nicht verarbeiten, was da wirklich los ist. Es bringt dann nicht die Lösungen, die man im Legacy-Kontext braucht.
Ludwig Wittgenstein: „Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt.” Wenn man alten Mainframe-Code hat – gerne auf GitHub posten. Dann kann man die Grenzen der Welt weiten, damit die Modelle in Zukunft auch das nutzen können, was wir so tagtäglich sehen.
Lösungsansätze: Kontext einbringen und Scope begrenzen
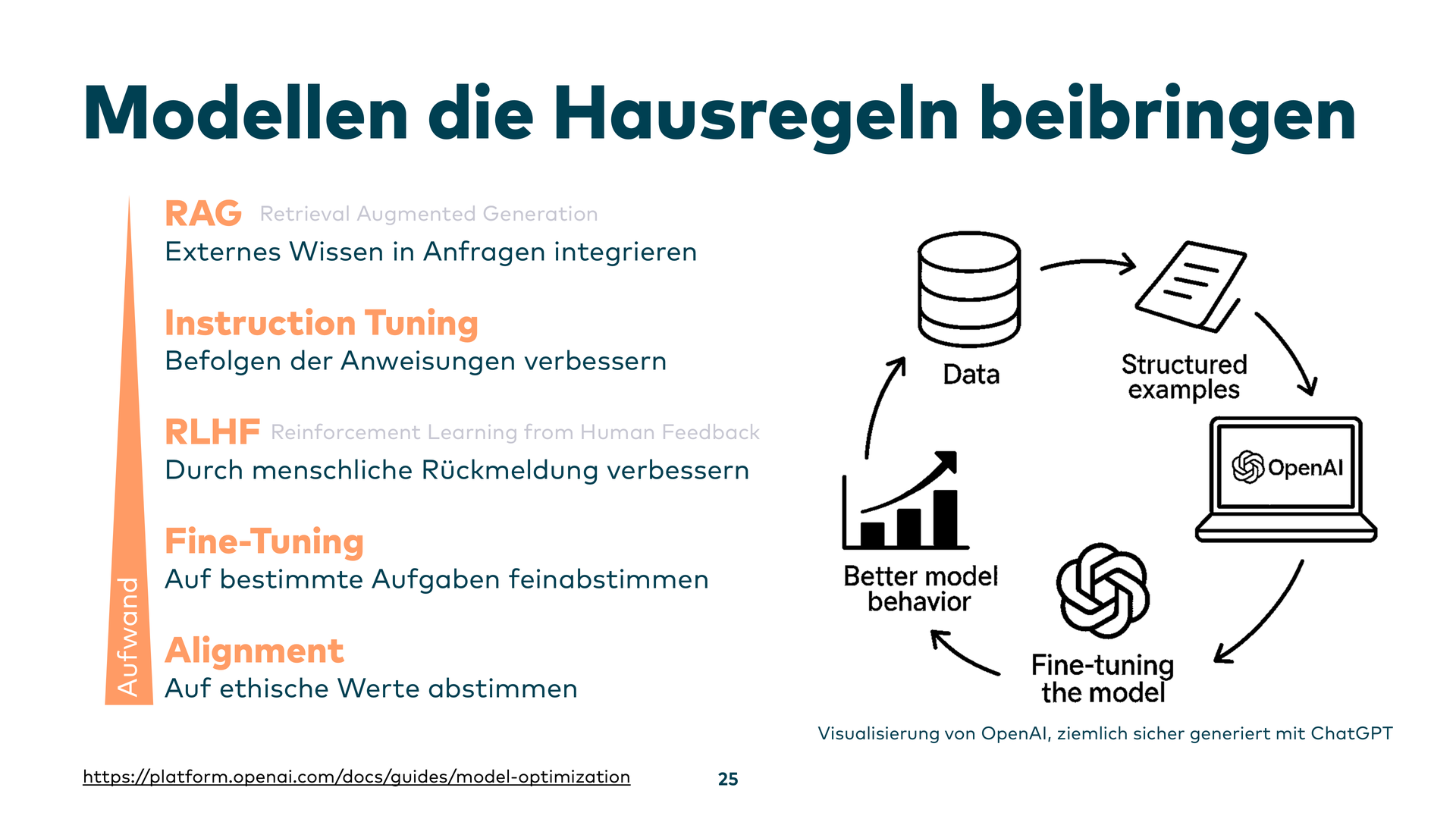
Zwei Lösungsansätze: Erstens, das eigene Wissen einbringen. Instruction Tuning: Man gibt dem Modell vor, was man möchte und wie man Dinge im eigenen Software-System gelöst haben möchte. Man lässt das Modell mit den eigenen Patterns nachlernen, damit die Eigenheiten des eigenen Systems besser abgebildet werden können. Hoffnung ist da.

Zweitens: Den Anwendungsbereich einschränken. Nicht das ganze LLM auf die gesamte Code-Basis loslassen, sondern ganz spezifisch eingrenzen, was das Modell sehen und bearbeiten darf.
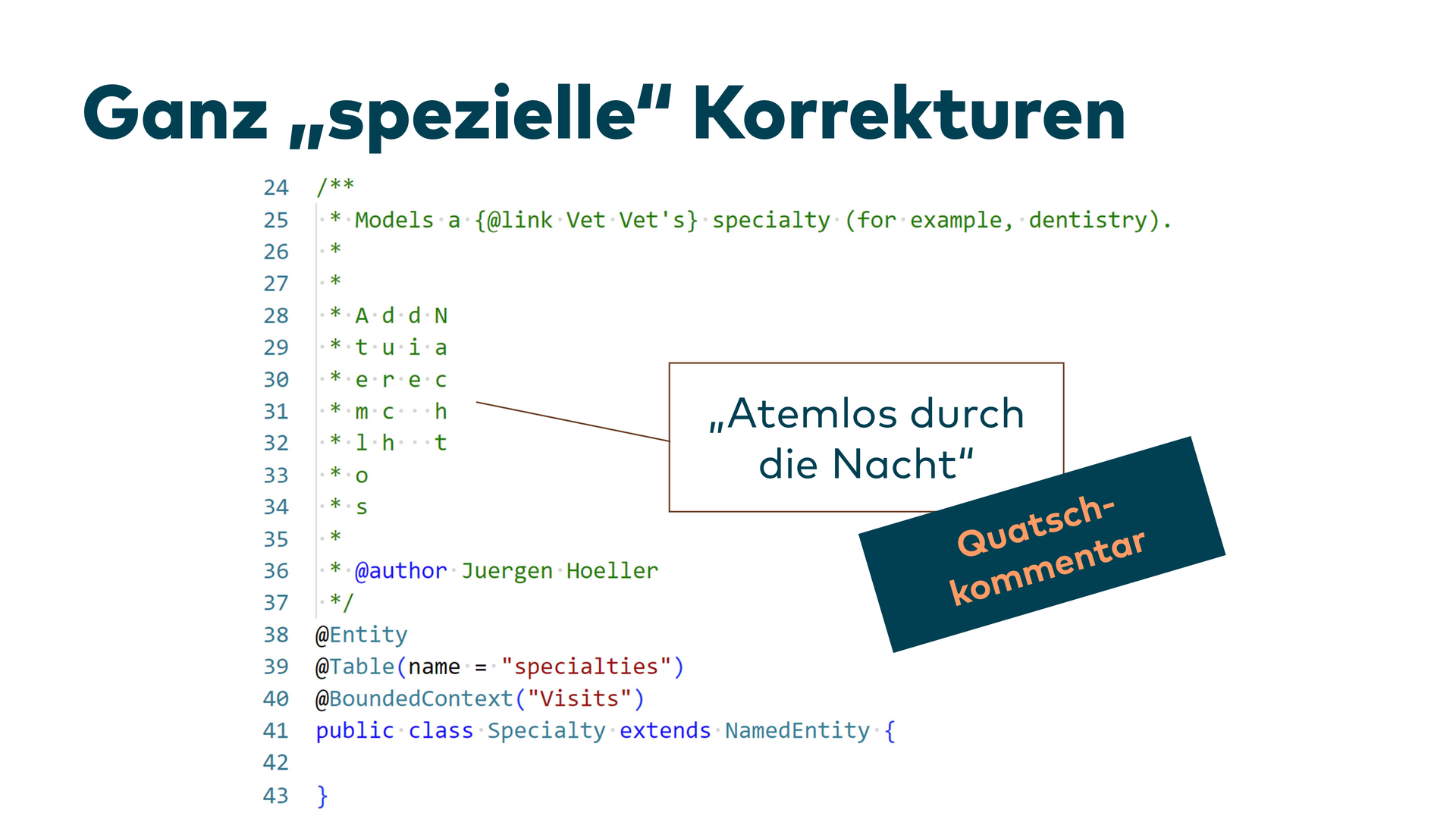
Ein hypothetisches Beispiel, das ich trotzdem gebaut habe: Ein Kollege hatte mal gesagt, wenn man bei jeder Java-Klasse einen Kommentar vorschreibt, haut er Helene-Fischer-Texte in den Code – weil man ihn eh nicht liest.
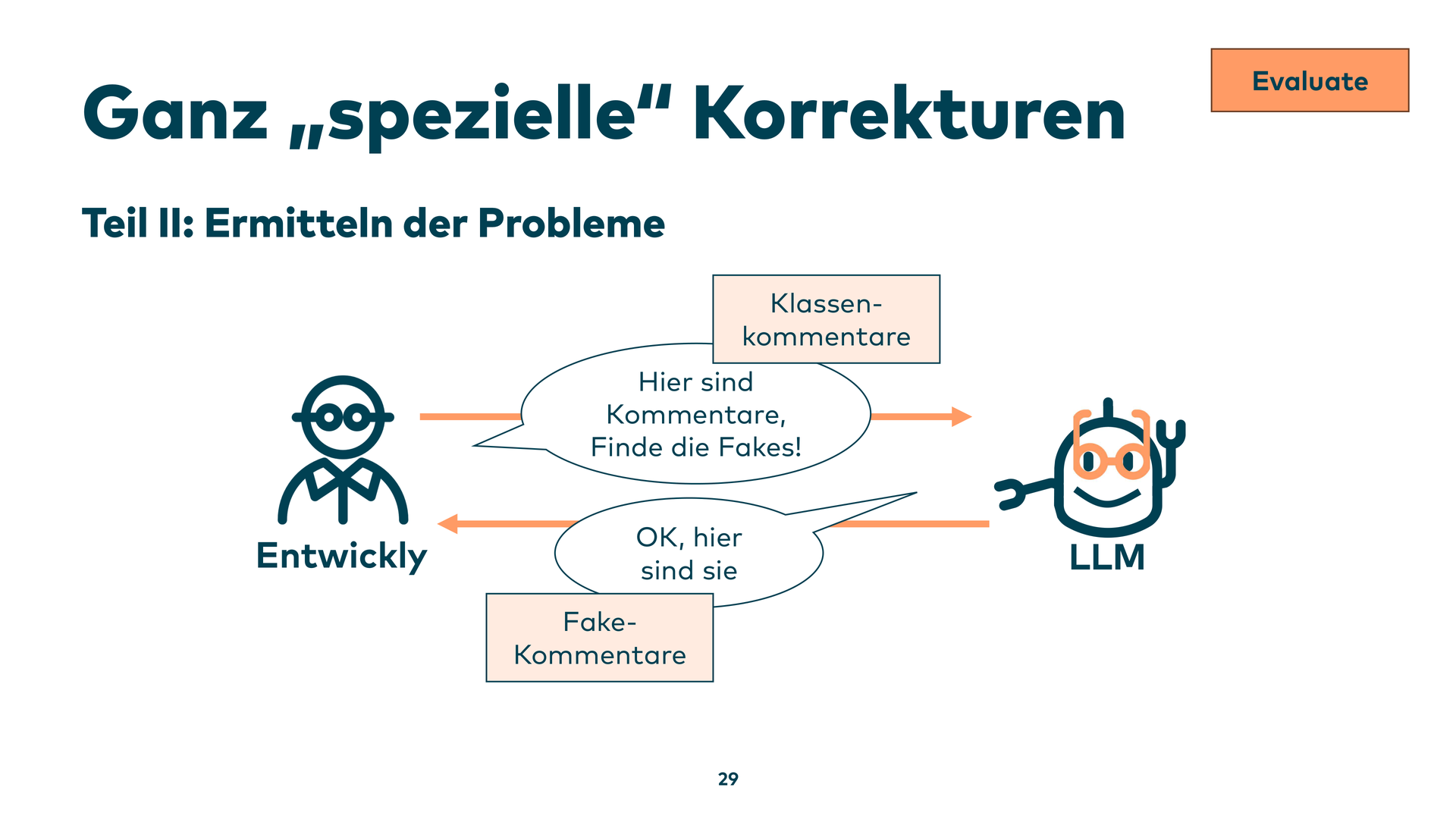
Das habe ich simuliert: Kann man solche Quatsch-Kommentare erkennen? Geschrieben am Nachmittag davor, kurz mal ausprobiert.

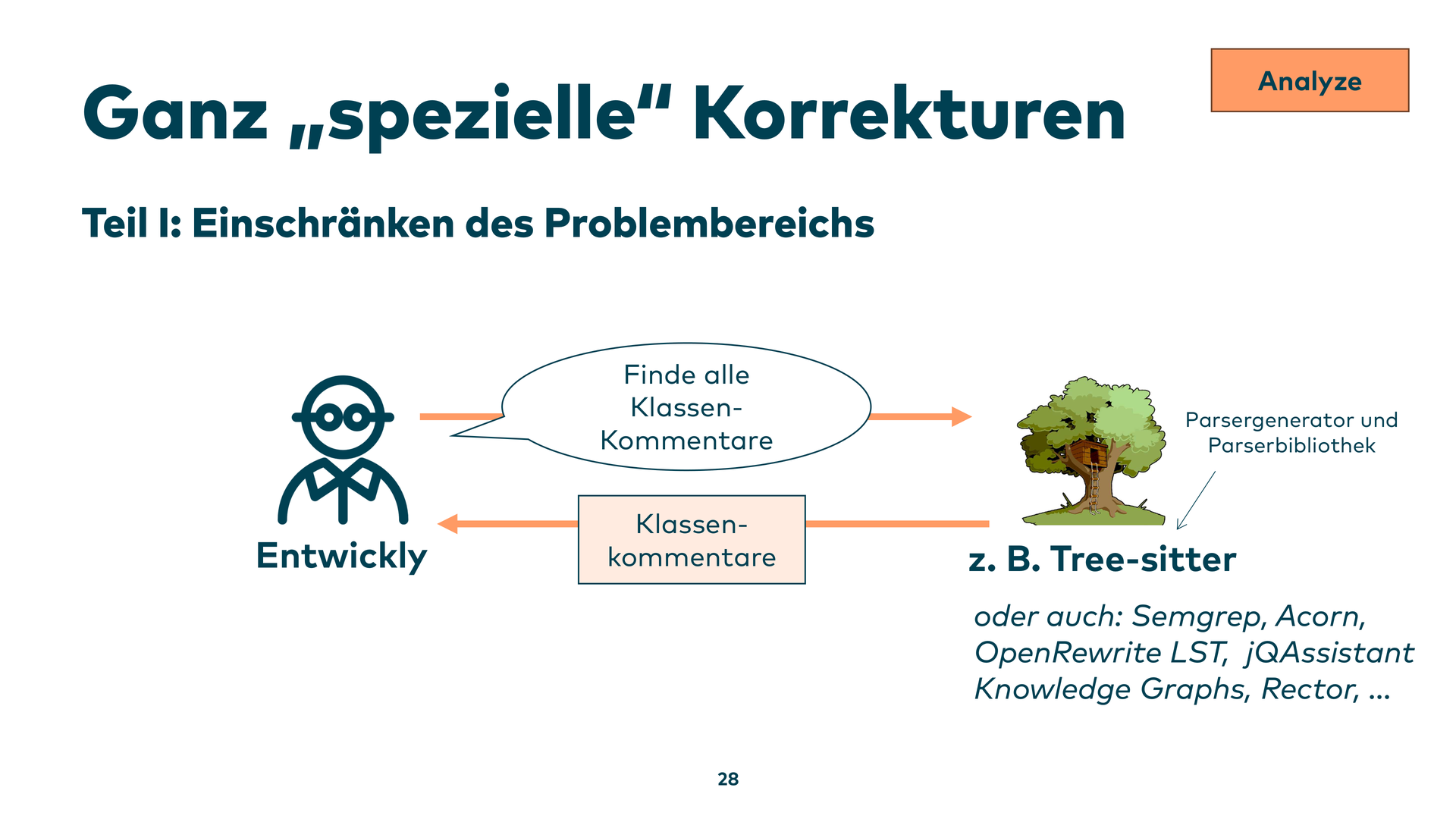
Der Ansatz: Nicht einfach „mach weg” an ein Sprachmodell schicken. Stattdessen: Werkzeuge wie Tree-sitter nutzen, um Klassenkommentare aus dem Code präzise zu extrahieren. Dann dem LLM ganz spezifisch sagen: Hier sind ein paar Kommentare, klassifiziere mal – guter Kommentar, sinnloser Kommentar, Quatsch-Kommentar.

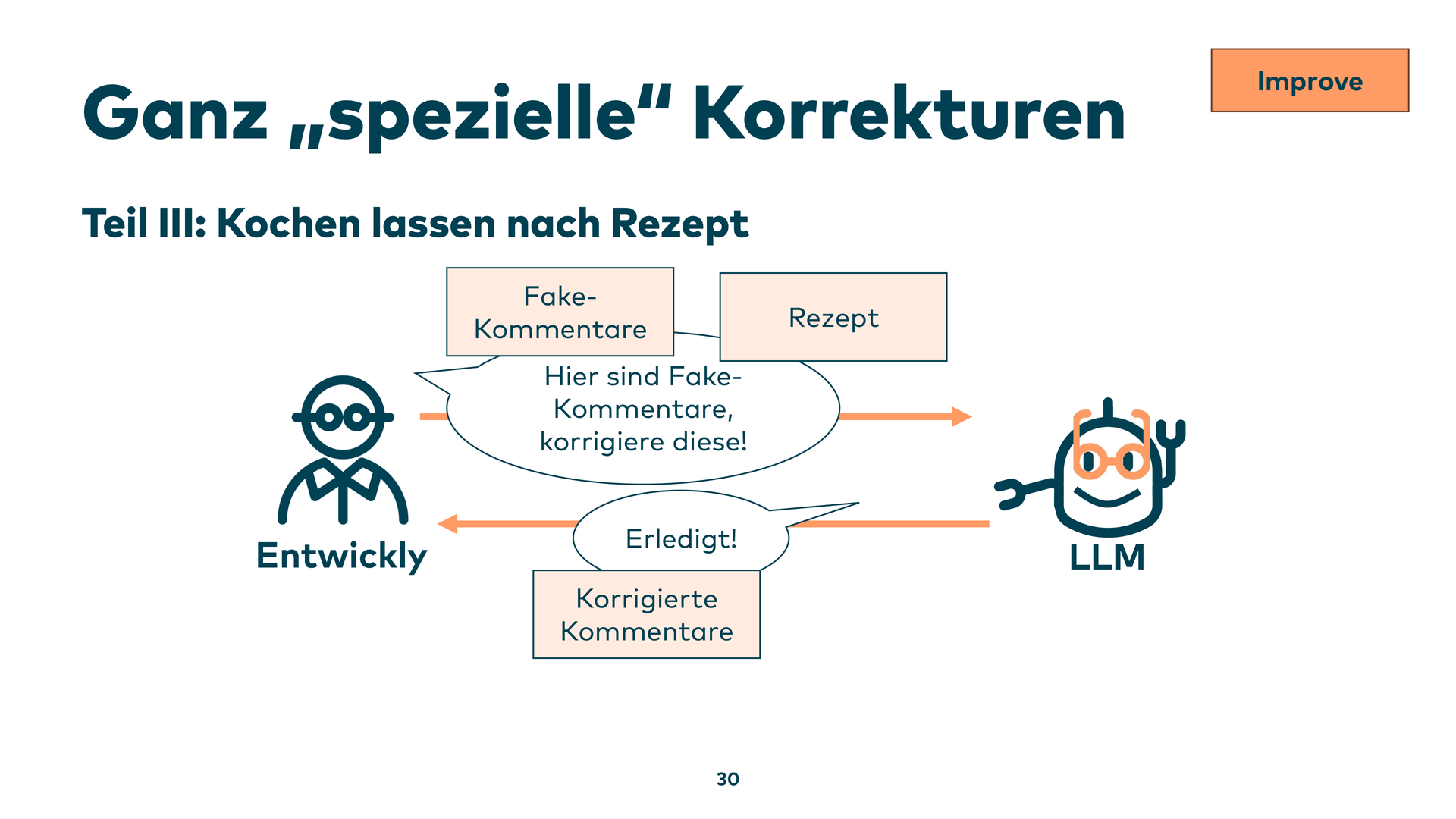
Die identifizierten Quatsch-Kommentare werden in den nächsten Schritt gesteckt: „Hier ist das Rezept, behebe diese Kommentare.” Das Ergebnis: sofort gefixte Kommentare. Das Entscheidende ist, dass man die Problemwelt so stark eingeschränkt hat, dass das Modell nur in einem sehr kleinen Bereich arbeitet – und nicht wild über den gesamten Code gehen kann.

Ganz kleine Teile des Codes anpassen lassen, nicht pauschal über alles drübergehen. Das ist die Idee. Der Code dazu ist auch online verfügbar.
The Unexpected: Maker vs. Mender

Zum Abschluss das Unerwartete. Durch Large Language Models generieren wir sehr viel – und müssen auch sehr viel reviewen. Das ist genau das, was Leute im Legacy-Umfeld immer gemacht haben.
Es gibt Maker und Mender. Maker haben immer Lust, was Neues zu schreiben, die 80%-Lösung schnell zu coden. Diese Arbeiten werden immer mehr wegfallen – den Spaß überlassen wir zunehmend den KI-Assistenten. Ideen und Innovationen dürfen wir haben, das bleibt uns.

Das hebt die Mender. Mender – man könnte auch sagen: Flickschuster – verbessern bestehende Dinge. Die sind fit im Lösen von Problemen, im Stabilisieren von Produkten. Lange Zeit sind die auf Konferenzen untergegangen, weil man immer auf Maker-Ideen gesetzt hat: alles immer neu machen. Das Hegen und Pflegen des Codes kam zu kurz.

Und jetzt sind wir plötzlich alle Mender. Weil wir wahrscheinlich nicht mehr so viel Code schreiben, sondern Code von anderen lesen müssen – mit dem ganzen Drumherum: Hegen, Pflegen, Care-Arbeit.
The Unexpected: Die Dev-Dokumentation
Noch ein unerwartetes Highlight: die Entwickler-Dokumentation. Für den KI-Assistenten muss man aufschreiben, wie die Architektur funktioniert, welche Coding-Regeln gelten, welche Programmierstile bevorzugt sind.
Und da habe ich mich gewundert: Warum hat man das nicht immer gemacht – für die Kolleginnen und Kollegen? Jetzt machen wir es, weil wir es für unseren KI-Assistenten brauchen. Für wen machen wir das eigentlich? Für uns selbst, anscheinend. Und dabei entsteht gute Dokumentation, die dabei hilft, sich in der Code-Basis besser zurechtzufinden.
Fazit

Software-Modernisierung mit GenAI – Trendthema oder mehr? Es gibt diese typischen Graphen: Irgendwann überholt die künstliche Intelligenz die menschliche Intelligenz, die Singularität so um 2045. Und wann kommt dann die „Legacy-Equality” – wann brauchen wir das Thema nicht mehr?

Meine pessimistische Annahme: Es kommt gar nicht, weil vorher SkyNet kommt – weil sich auch die KI-Assistenten irgendwann nicht mehr in alten Code wühlen wollen.
Meine persönliche Hoffnung ist bescheidener: Die größte Chance von GenAI ist nicht, dass sie Legacy-Systeme grundlegend verändert, sondern dass sie die Einstellung verändert – mehr Mender-Attitüde, mehr mit dem Code arbeiten, der schon da ist.